
MACHINE LEARNING APLICADO A LAS EMPRESAS | Parte 2

Andrés Villamizar | Ingeniero electrónico. Account Manager para SOLEX.
El machine learning por sector
Hoy en día Podemos observar el machine learning presente en prácticamente todas las industrias. Un gran referente para la industria automotriz es Tesla, el gigante estadounidense desarrolla Machine Learning para sus automóviles de conducción semi-autónoma. Ver imagen 1.

Google, uno de los pioneros del machine learning, cada vez perfecciona más sus modelos para generar búsquedas más rápidas y acertadas.
Por su parte Facebook requiere que las imágenes que se suben a su plataforma, sean rápidamente validadas para impedir que contenido indebido sea cargado y reproducido por millones de personas.
Uno de los avances más significativos en la industria del machine learning es el reconocimiento de voz; CORTANA la máquina de reconocimiento de voz de Microsoft es uno de los máximos representantes en su género.
Para el sector energético, grandes compañías deben evaluar las variaciones de potencia en su tendido eléctrico. Grandes volúmenes de información se están presentando constantemente debido a la cantidad de variables que se presentan; si el machine learning es utilizado para predicciones como el robo de cableado, efectos del clima, o deterioro del tendido eléctrico, esto puede representar grandes beneficios económicos para este sector.
El machine learning, no solo es data interna de las empresas
Gracias al Big Data, cada industria tiene suficiente información externa para alimentar sus propios modelos. Por supuesto es absolutamente requerido tener información interna y detallada de las industrias, pero es la información externa, la que sirve como gran apoyo para enriquecer los modelos, volviéndolos competitivos y eficientes.}.
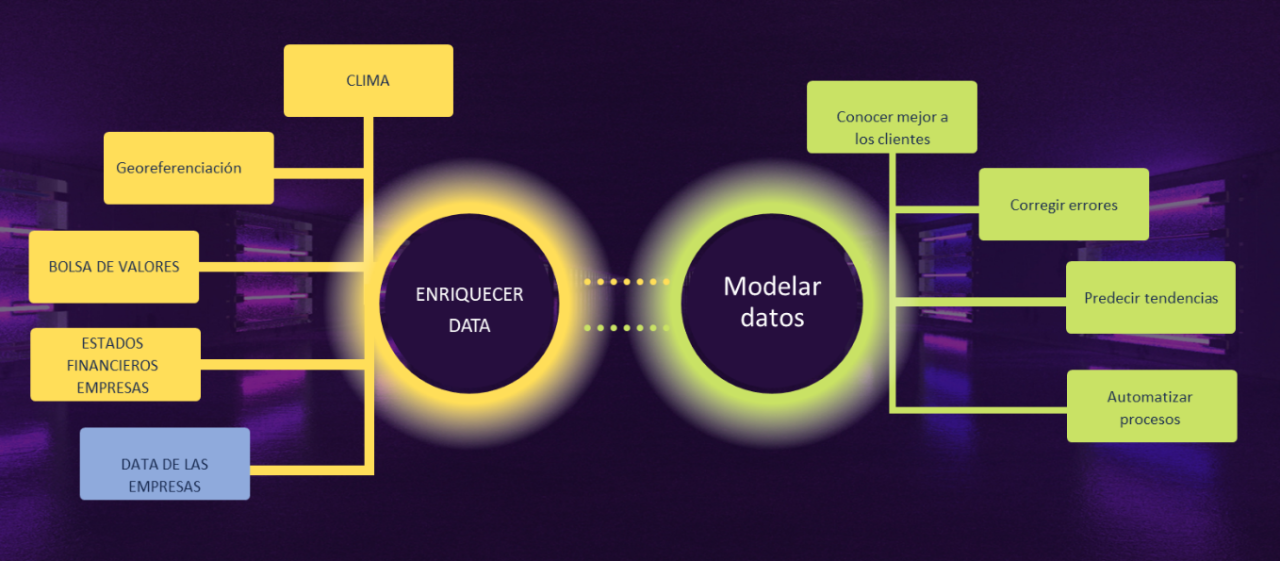
Hoy en día es de fácil acceso información tal como el clima, georreferenciación, estados financieros de empresas y todo esto suma información a la propia data de la empresa (costado izquierdo de la imagen 2). Toda esta información enriquece los modelos actuales de datos; así las cosas, se pueden establecer mejores modelos de datos y tener información relevante para el negocio, como por ejemplo conocer mejor a los clientes, corregir errores, predecir tendencias y automatizar procesos (ver costado derecho de la imagen 2).
El modelado de datos vs la programación tradicional
La programación tradicional permite incluir ecuaciones matemáticas ya conocidas para entregar un resultado, a partir de los datos de entrada.
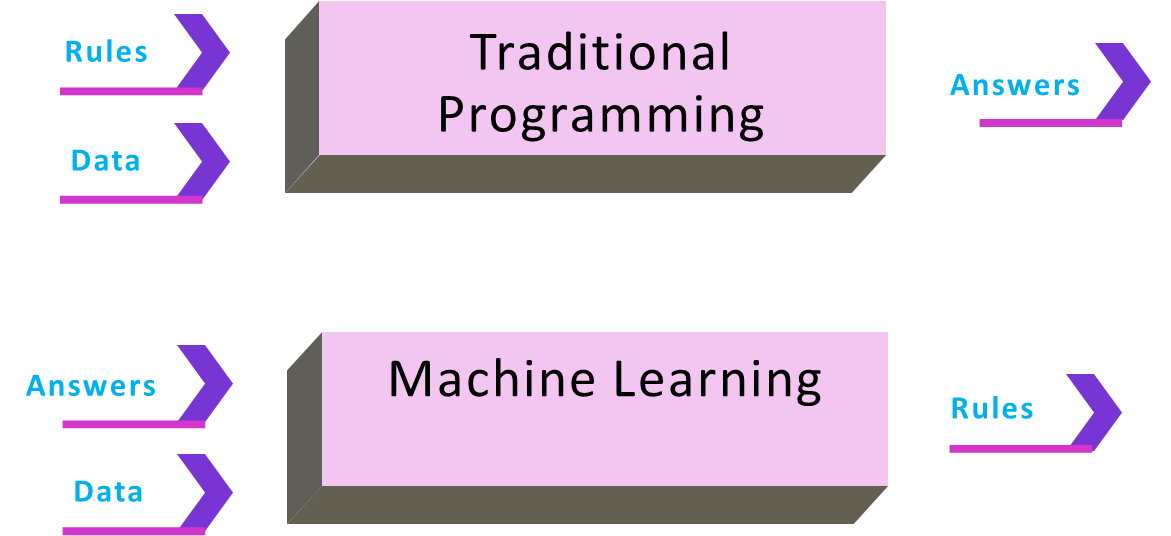
Para el caso del machine learning es distinto, se requiere que a partir de datos de entrada y datos de salida, se construya la ecuación matemática que conectará posteriormente las entradas con las salidas.
Gracias al software y a los avances en materia de velocidad, y almacenamiento de los computadores actuales, el machine learning brilla más que nunca. Ya que los modelos matemáticos se deben ajustar constantemente y se requiere máquinas que realicen lo más rápido posible estas iteraciones para el respectivo ajuste accediendo a múltiples fuentes de datos, tanto internas como externas.
Software para modelado de datos
Otra de las razones para concluir que hoy más que nunca el machine learning forma un papel muy importante en la industria, es la variedad de lenguajes de programación que se están enfocando en los datos. Ver la imagen 4.
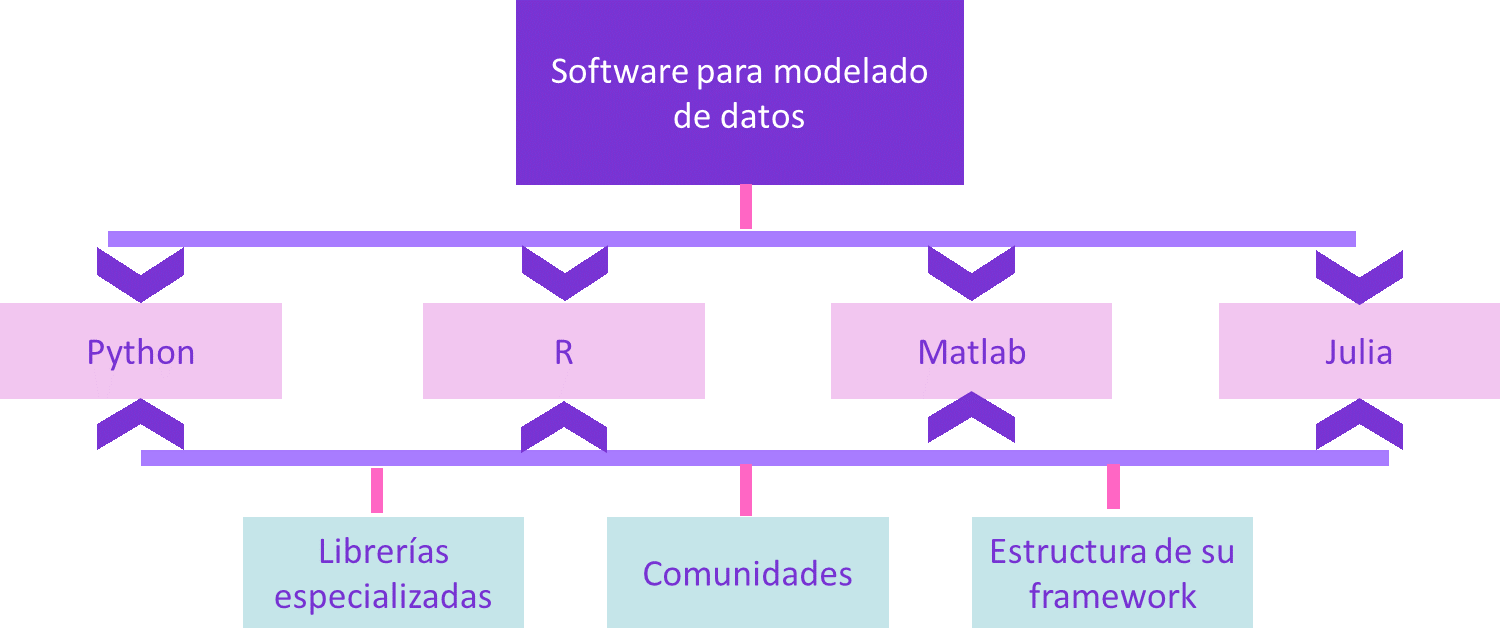
Python y R se posicionan como los líderes en cantidad de uso por parte de los programadores, acaparan la mayor cantidad del mercado de desarrollo de Machine Learning. Julia y Matlab son fuertes jugadores en el sector.
Grandes características como librerías especializadas, encontrar grandes comunidades de apoyo, y un framework especializado en datos, hacen que estos lenguajes sean líderes indiscutibles del sector.
Dataiku es la plataforma líder para elaborar machine learning de forma colaborativa
Ver también soluciones de dataiku
Hoy en día los grandes modelos de datos elaborados por científicos de datos están quedando en el pc de cada uno de ellos y posteriormente desplegado en algún servidor de la empresa.
Normalmente los modelos de datos requieren ser modificados y ajustados; para lo cual se debe requerir de nuevo que los científicos de datos ingresen a su pc personal, modifiquen el modelo y lo vuelvan a cargar en el servidor de la empresa.
Los modelos de datos no se desarrollan de un día para otro; requieren de meses y hasta años de matemática y desarrollo para llevarlos a cabo. Por lo que podríamos concluir que elaborar un modelo de datos, puede costar miles de dólares, de acuerdo a su complejidad.
Todo lo anterior, imaginando que el científico de datos va a estar siempre vinculado a la empresa; pero ¿qué ocurre si el científico de datos sale de la empresa?, tal vez nadie vuelva a entender el desarrollo que realizó, quizás no lo documentó lo suficiente, o posiblemente no tuvo cuidado y lo borró.
Por todo lo anterior, es necesario garantizar que una plataforma permita elaborar en ella los modelos de datos, además de permitir la traza de los cambios y que estos cambios se encuentren bien documentados.
La plataforma que permita realizar todas estas bondades, debe garantizar la ejecución de un modelo simple, como se muestra en el siguiente diagrama:
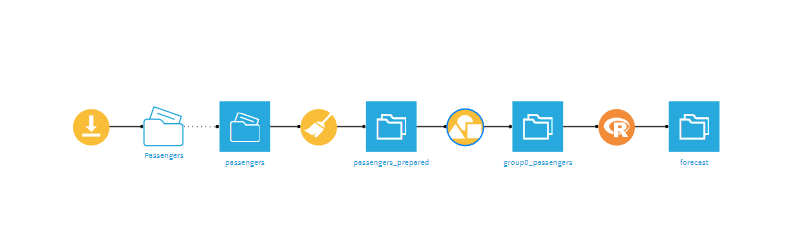
De la anterior imagen, las cajas azules son datos y los demás se llaman recetas, veamos cómo funciona:
- De izquierda a derecha se puede inferir que hay una carga de datos (ícono de carga naranja),
- Posteriormente se ve que la información cargada es de pasajeros (primer ícono de datos azul),
- Seguido de una limpieza de datos (ícono escoba, color naranja), la cual permite retirar espacios, quitar datos duplicados entre otros cientos de tipos de limpieza de datos.
- Posteriormente se observa un nuevo ícono de datos (datos limpios).
- Hay un ícono de modificación datos (ícono de figuras geométricas)
- Y finalmente un ícono del lenguaje de programación R, el cual permite realizar un modelo de datos, para cierta información de pasajeros que ingresó; y así entregar una predicción de pasajeros.
El anterior es un modelo tan simple, que posiblemente funcione muy bien desde el computador del científico de datos, y este lo pueda documentar muy bien, y desplegarlo en un servidor.
¿Pero que ocurre cuando se requiere lo siguiente?
- Elaboración de múltiples modelos de datos.
- Muchos científicos desarrollando y colaborando entre ellos.
- Consultar múltiples fuentes de datos.
Hoy por hoy, han llegado plataformas muy interesantes de inteligencia artificial, las cuales permiten colaboración en las corporaciones data driven, para que gestionen su Machine Learning. Una de ellas es DATAIKU, plataforma end to end (permite la carga, gestión y visualización de los datos), ver imagen 6.

DATAIKU permite que en la compañía se elabore cantidades de modelos de datos sin límites; Además que en la exista colaboración tanto horizontal (entre científicos de datos) como vertical (entre diferentes áreas). Con DATAIKU se puede llevar la traza de todos los cambios que un científico realiza en su modelo de datos; además permite que el científico ejecute en DSS (el software de desarrollo de dataiku) todos los cambios de su modelo de datos en Python, R, Juli, Matlab, entre otros y tenga acceso a recetas, análisis de datos y visualización.
Dataiku permite que en las organizaciones exista la democratización de los datos, además de la implementación gradual de Machine Learning.
Cuando al año en la organización se ha invertido en dinero, tal vez entre USD$20.000 Y USD $40.000 a un solo modelo de datos y además tenemos varios científicos desarrollando otros modelos para cada caso de uso, es debido que una plataforma profesional orqueste todo este proceso. Para ello dataiku, está posicionada como líder indiscutible en el cuadrante de Gartner.
Related Entradas

MACHINE LEARNING APLICADO A LAS EMPRESAS | Parte 1
SOLEX explica cómo el machine learning está siendo decisivo en la evolución de las empresas.…

Descargue la Versión de Prueba de Tableau Server
Prueba Tableau ServerAnálisis para todos y en cualquier lugar Capacite a los miembros de su…
Solex & Tableau la mejor alternativa para empresas.
Aproveche el análisis de los datos, para impulsar el rendimiento de las ventas. Solex &…